A workflow for distributed parallel data analysis on HPC with checkpoint
A typical task we do nowadays is to submit a job to the cluster to run some data analysis. But there are some limitations we can do as I know, to some extend.
Lots of tasks take a long time to run, which means the Walltime must be large even with multiple cores; HPC queue is busy and it takes forever to wait in the queue; If a job failed, we have to start over; Therefore, I have designed a protocol with workflow to resolve these issues.
- It uses MPI for parallel computing, so we can make use of multiple nodes to speed up;
- It provides a checkpoint feature, so it can restart if something went wrong;
- It supports automate resubmit if the Walltime is not enough.
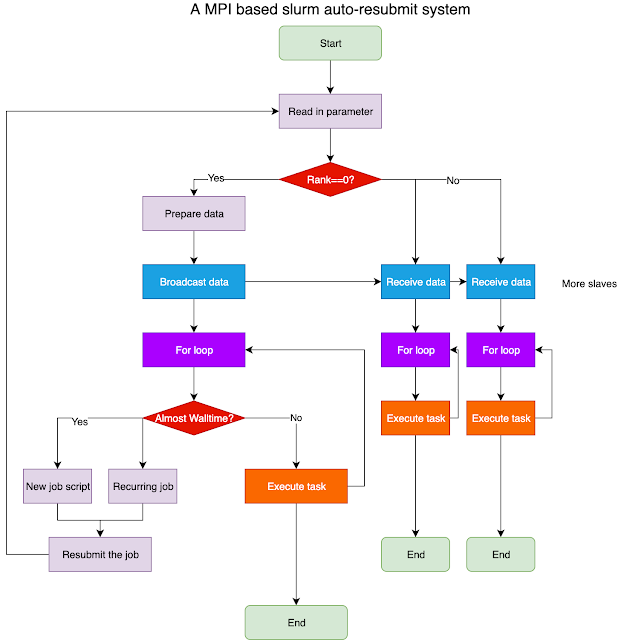
There are several implementations depending on the system. For example, on the SLURM system, a recurring job method can be used.
This design is expected to be able handle normal operations. However, there is a catch. It makes some assumption about the work load of individual slave node: it assumes that within each walltime, all the slave node should be able to finish the task.
Normally, the slave node will receive only a small fraction of the whole task and finish it on time. However, if the work load is not uniform, i.e., some nodes may experience slow down whereas others are fast, this work could fail.
Ideally, the workflow should keep track of individual node status so we can restart failed ones easily.
A work-around method would be Parafly. If we can physically decompose the task into individual tasks, it would be much easily to rerun some slaves.